Data Hunger
How Embodied AI Turns Manufacturing Scale into a Strategic Asset

Inside a brightly lit facility in Beijing’s Shijingshan district, a young man wearing a virtual-reality headset and arm exoskeletons repeats a single motion hundreds of times. He is opening the door of a microwave. Gripping the handle, pulling at the right angle, feeling the slight resistance of the latch—each attempt generates a stream of data that flows into the humanoid robot beside him, teaching it the physics of an action most humans perform without a thought. The trainers at this facility call themselves “cyber-laborers.”

The tedium is justified by the numbers. Across the embodied AI industry, global demand for high-quality training data runs to roughly 1.2 million hours, yet total monthly output sits at only 250,000 to 300,000 hours. That is the conservative estimate. Others in the field put the gap far wider: mature datasets amount to merely hundreds of thousands of hours, while training a truly capable model may require tens of millions. Try asking a robot to crack a walnut, and the magnitude of the challenge becomes visceral—it squeezes too hard and crushes the nut, every single time, because it has never felt the subtle give of a shell about to split.
The bottleneck is structural, not temporary. Large language models can gorge on the entire written internet—trillions of words scraped, cleaned, and fed into training pipelines. A robot has no such luxury. The data it needs—contact force, friction coefficients, the way a plastic container deforms under pressure, the improvisation required when a grasp fails—must be generated one action at a time, in real physical environments, by real hands. You cannot download physics.
The Data Bottleneck That Cannot Be Downloaded
When the decisive resource in AI shifts from computing power to physical-world data, the rules of competition change with it. Processors can be purchased, algorithms can be lured with salaries, but data must be produced—at scale, continuously, in messy real environments. That simple fact recasts the geography of advantage: manufacturing scale itself becomes a data-generating infrastructure.
A report from Georgetown University’s Center for Security and Emerging Technology identifies a telling divergence. China treats embodied AI—the integration of artificial intelligence into physical machines—as a primary pathway to artificial general intelligence. The United States, by contrast, has placed its bets largely on large language models and frontier algorithms. The two countries are not merely pursuing different technologies; they are allocating resources toward fundamentally different assets. China bets on factories and training fields. The United States bets on GPU clusters and foundation models.
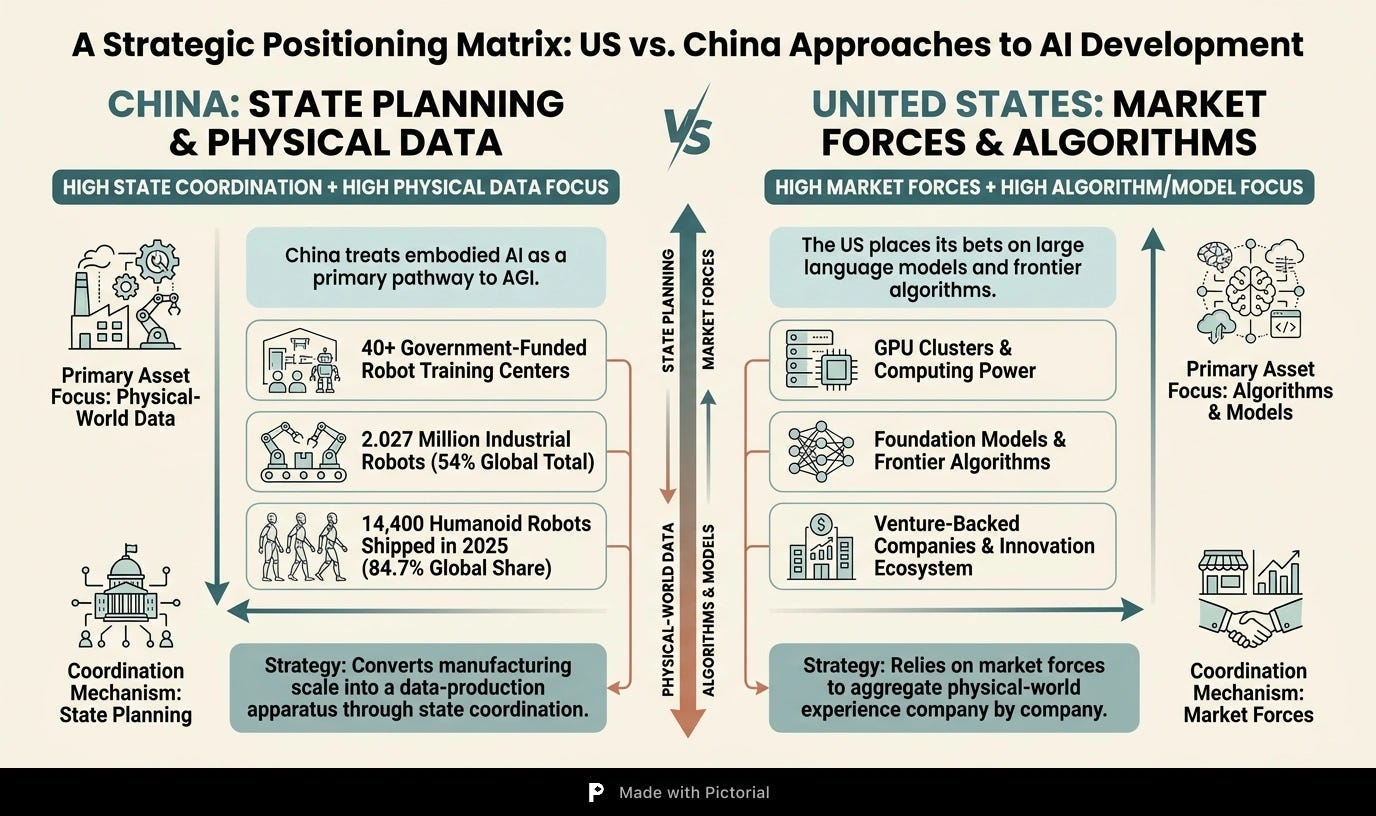
The American side is not ignoring physical data. Figure AI has partnered with Brookfield Asset Management to collect data across 100,000 households. Scale AI has already accumulated 100,000 hours of training video. Tesla employs dozens of workers who act out motions for its Optimus humanoid. These efforts are real, but they are market-driven, venture-backed, and scattered. The contrast is one of method, not ambition.
The core divergence boils down to this: China is converting manufacturing scale into a data-production apparatus through state coordination, while the United States relies on market forces to aggregate physical-world experience one company at a time.
China’s Data Infrastructure Play
Zoom out from the single trainer in Shijingshan and the scale of China’s data infrastructure becomes visible. By late 2025, more than forty government-funded robot training centers were operating across the country. The Shijingshan facility alone houses nearly 270 robots running at full capacity, producing close to 20 million data entries per year. A separate data base run by the Beijing Humanoid Robot Innovation Center deploys over 120 machines generating 15,000 hours of data each month with a quality-acceptance rate above 95 percent. China’s Fifteenth Five-Year Plan explicitly embeds “training grounds” into the national industrial system—a policy detail that Six Degrees of Robotics, an industry newsletter, calls the most underrated clause in the entire plan.
Beneath these training centers lies a deeper foundation. China operated approximately 2.027 million industrial robots in 2024—4.5 times the number in Japan—and installed 295,000 new units that year, accounting for 54 percent of the global total. In 2025, the country shipped 14,400 humanoid robots, representing 84.7 percent of global shipments and roughly nine times the American figure. The Fifteenth Five-Year Plan’s training-ground provisions, in Six Degrees of Robotics’ analysis, are converting what was merely an incidental byproduct of manufacturing—robots generate data simply by working—into an explicit “data moat.”
This infrastructure buildout is already creating tangible economic effects on the ground. In China’s third- and fourth-tier cities, a new occupation has emerged: the data collector. Wang Yanan, a former food-delivery rider in Shanxi province, now earns 6,000 to 7,000 yuan a month recording himself folding clothes, wiping tables, and making sandwiches while wearing data-capture equipment. At Longyu Big Data, a collection team of 100 people is 60 percent stay-at-home mothers working part-time for 3,000 to 4,000 yuan a month. The work is migrating from megacities to smaller towns where land and labor cost less.
Yet the buildup carries risk. The sector attracted 73.5 billion yuan in investment during 2025, with Shenzhen alone establishing a 10-billion-yuan AI and robotics fund. In November 2025, the National Development and Reform Commission issued a rare public warning about bubble risks in the humanoid robotics industry. Interact Analysis has echoed concerns about overcapacity. The pattern mirrors China’s electric-vehicle policy a decade earlier: heavy public procurement to nurture an infant industry, yielding both a global competitive position and a trail of excess factories. Whether embodied AI will follow the same arc remains genuinely uncertain.
The torrent of data flowing from these training centers, however, is not staying within China’s borders. It is spilling outward through an unexpected channel: open source.
Open Source as Ecological Strategy
In 2025, Shanghai-based AgiBot released its AgiBot World dataset into the open-source community. The numbers are striking: over one million atomic action trajectories, 850 terabytes of data, covering 217 tasks and more than 3,000 objects. Its long-horizon data scale is ten times that of Google’s Open X-Embodiment dataset. But the real story emerged in March 2025, when NVIDIA launched GROOT N1, its flagship humanoid-robot foundation model, at the GTC conference. Eighty percent of GROOT N1’s training data came from AgiBot World. A dataset produced by a Chinese company became the primary fuel for the world’s most prominent humanoid AI model.
Open-source data contribution is not merely generosity. When researchers and companies worldwide train their models on datasets structured around Chinese data formats and standards, those standards become embedded in the global research pipeline by default. A broader pattern is taking shape—”open-source datasets, joint laboratories, and regional collection centers”—with Leju Robotics launching China’s first open-source embodied AI dataset community, OpenLET, whose LET series has accumulated over one million downloads and 60,000 minutes of data covering 117 skills.
The contrast with China’s state-driven model is instructive. Distributed, low-cost alternatives do exist. Noematrix’s RoboPocket system turns a smartphone and a gripper into a portable data-collection node, with built-in real-time quality screening that evaluates each frame against model-training needs. The UMI (Universal Manipulation Interface) platform developed at Stanford costs roughly $500 to assemble. These tools suggest that meaningful participation in embodied AI data production does not require a billion-yuan training center.
The Question of Data Justice
When data becomes the core competitive resource in AI, the rules of the game are being rewritten in real time.
The risk of marginalization for Global South countries is not theoretical. They enter this new contest without algorithmic advantage and without data at scale. China’s model—forty-plus training centers, hundreds of billions in investment, manufacturing scale converted into a data moat—is not replicable for most developing nations. India offers an alternative path, with companies like Objectways producing 1,000 hours of data daily through labor-intensive egocentric video collection, but the volume remains a fraction of what China’s infrastructure generates.
Yet the window has not closed entirely. Geographic diversity in training data has inherent value. A robot trained exclusively in climate-controlled Chinese factories may struggle with the humidity of Lagos, the dust of Ahmedabad, or the cramped kitchens of Manila. This is precisely why Micro1, a Palo Alto-based company, has hired thousands of gig workers in over 50 countries—Nigeria, India, Argentina—to film themselves doing household chores. In Nigeria, a medical student named Zeus earns $15 an hour strapping an iPhone to his forehead and recording himself folding laundry. In the Philippines, sixty teleoperators in Manila monitor robots restocking convenience-store shelves across Tokyo, each operator overseeing roughly 50 machines, earning $250 to $315 a month. Their recovery interventions—stepping in when a robot drops a can, roughly four percent of the time—are simultaneously generating the training data that Physical Intelligence, a San Francisco startup, uses to develop fully autonomous models.
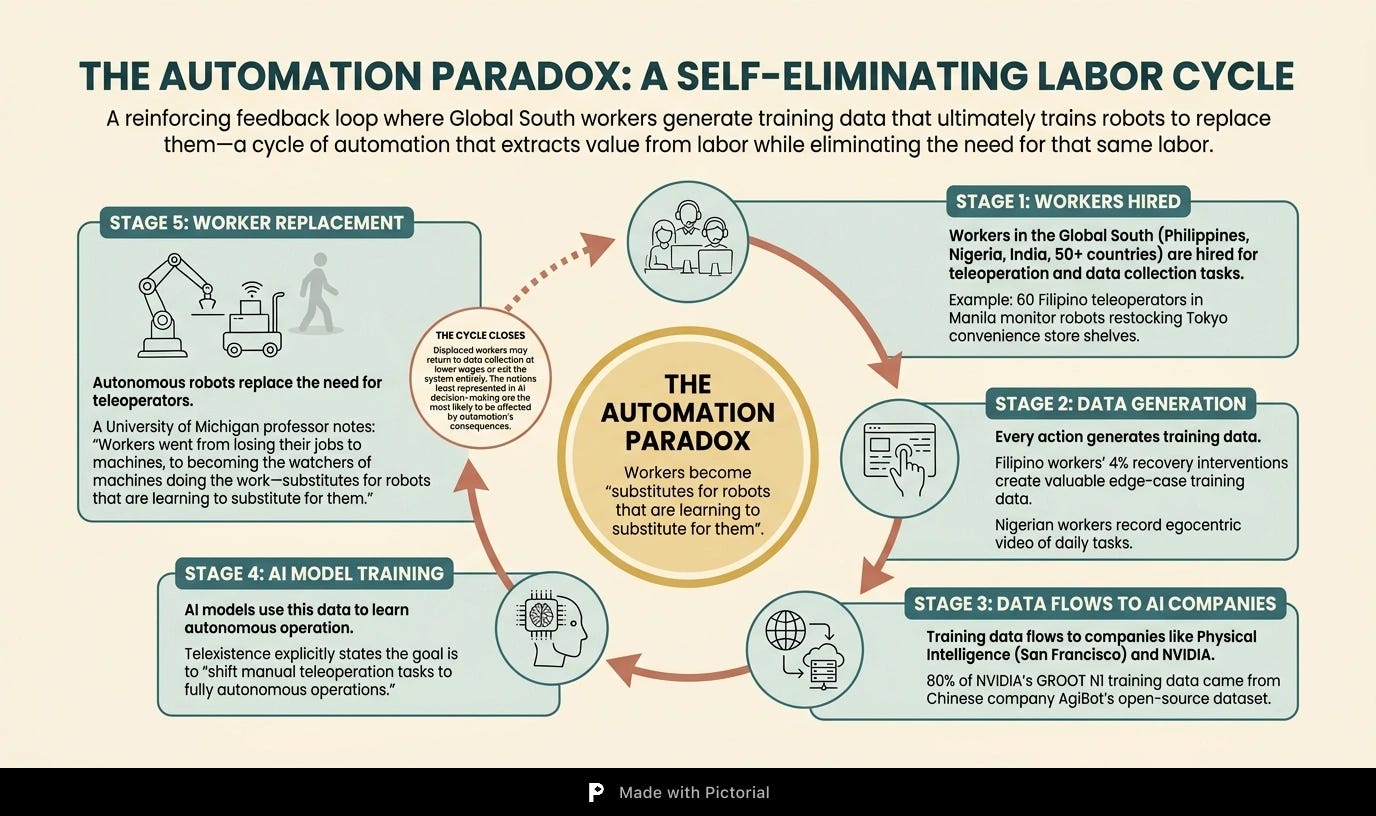
That Filipino case carries a symbolism that is hard to ignore. The teleoperators are generating data that will train robots to replace them. Telexistence, the Japanese company deploying the bots, has stated explicitly that the partnership aims to “shift these manual teleoperation tasks to fully autonomous operations.” A computer-science professor at the University of Michigan put it plainly: workers went from losing their jobs to machines, to becoming the watchers of machines doing the work—substitutes for robots that are learning to substitute for them.
The question that lingers is not whether the data hunger of embodied AI can be fed. China has shown that with enough political will and manufacturing scale, it can. The question is who gets fed in return, and on what terms. When a worker in Manila trains the robot that will one day stock shelves without her, when a dataset from Shanghai becomes the foundation for a model built in Silicon Valley, and when the nations least represented in the data are the most likely to be affected by its consequences, the challenge extends beyond technology. It becomes a question of how the value chain of physical intelligence is structured—and whether the Global South can find a place within it that is more than a source of cheap labor and diverse scenery for someone else’s robots.